Onslaught of clicks to move a single sprint
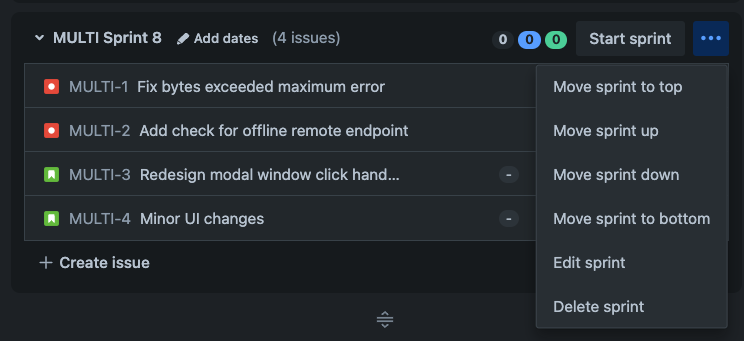
My engineering team conducts sprint planning sessions fortnightly. We create a new sprint in Jira ahead of time and refine our list of issues we want to tackle for the upcoming sprint during sprint planning. New sprints are always created at the bottom of the backlog in Jira. We like to keep our upcoming sprints together at the top of our backlog because we have several other long-living sprints that should remain at the bottom of the backlog.
One issue the team quickly became frustrated with is that we only have a move sprint up and move sprint down action for moving sprints. This means that in our backlog of typically ~10 sprints our scrum master would have to click the move sprint up action 10 times to reach the top of the backlog.
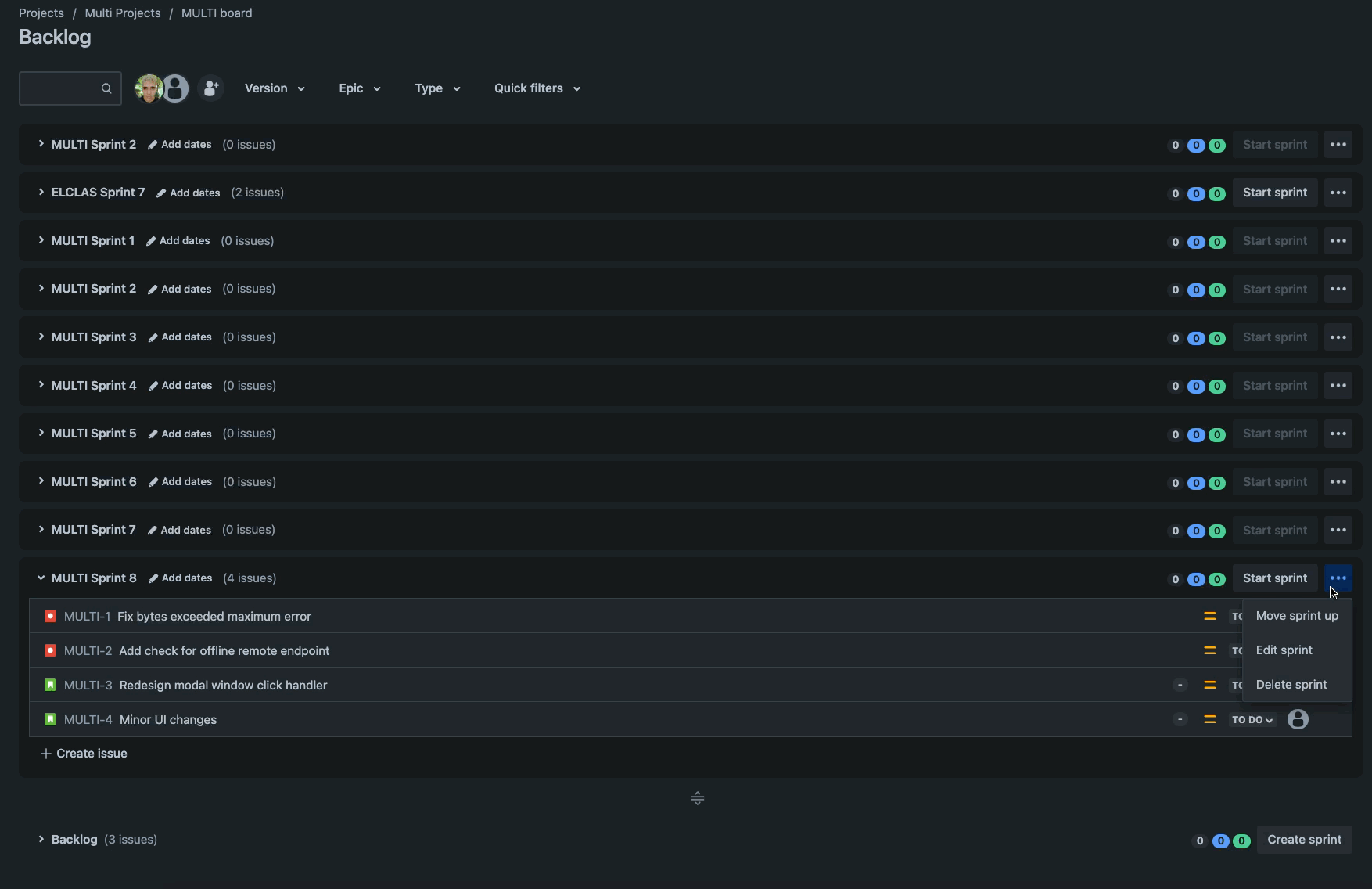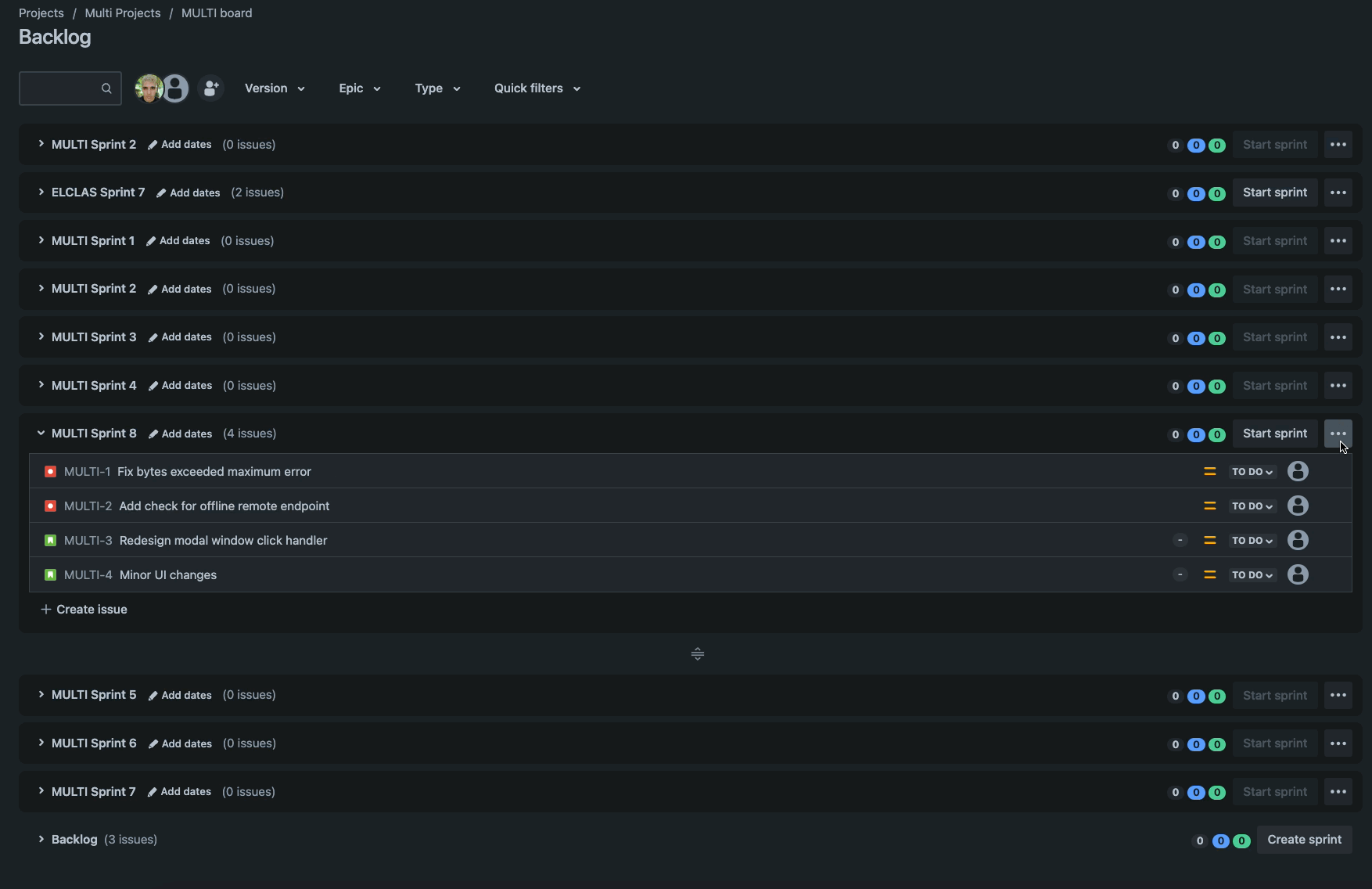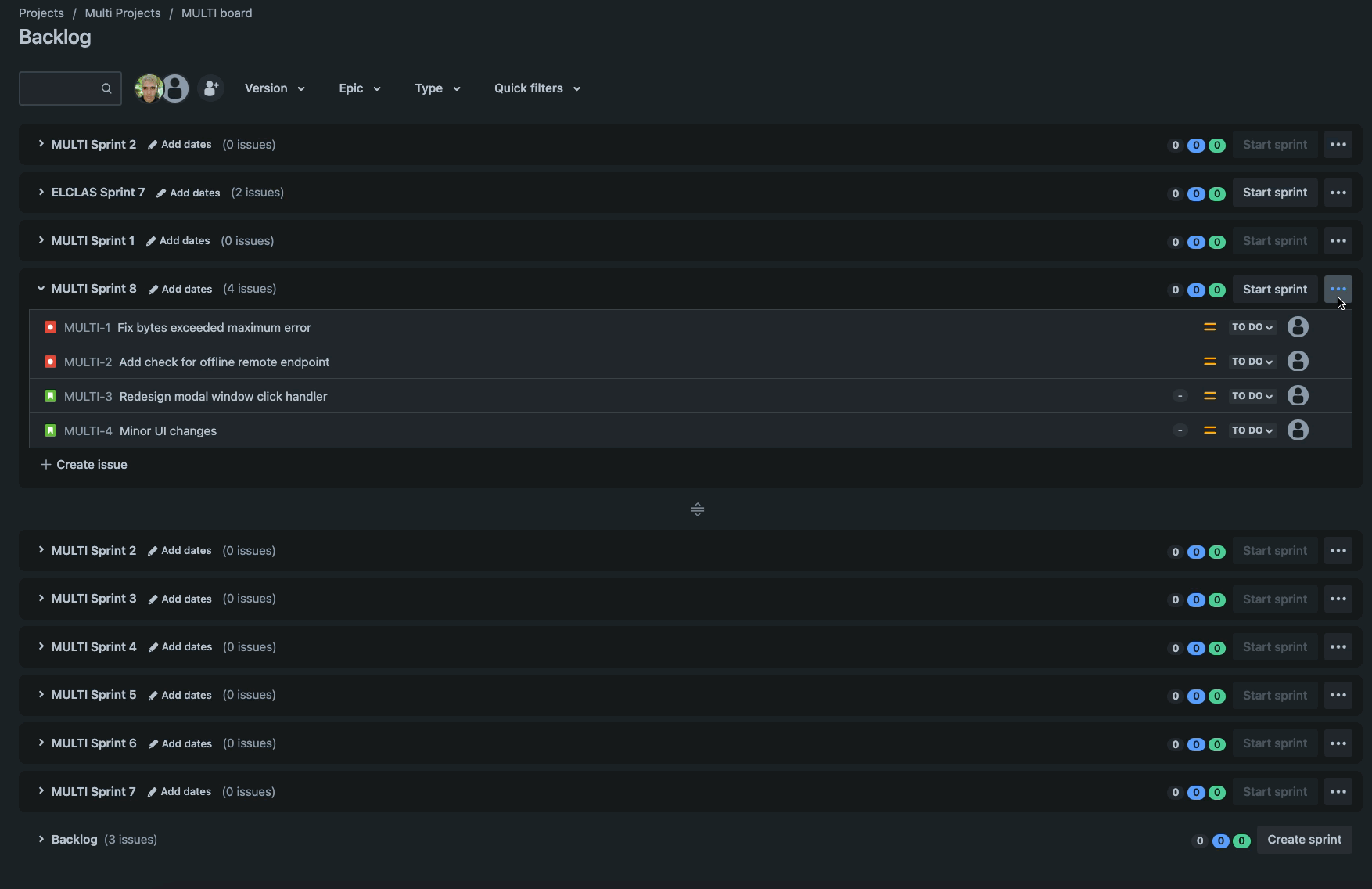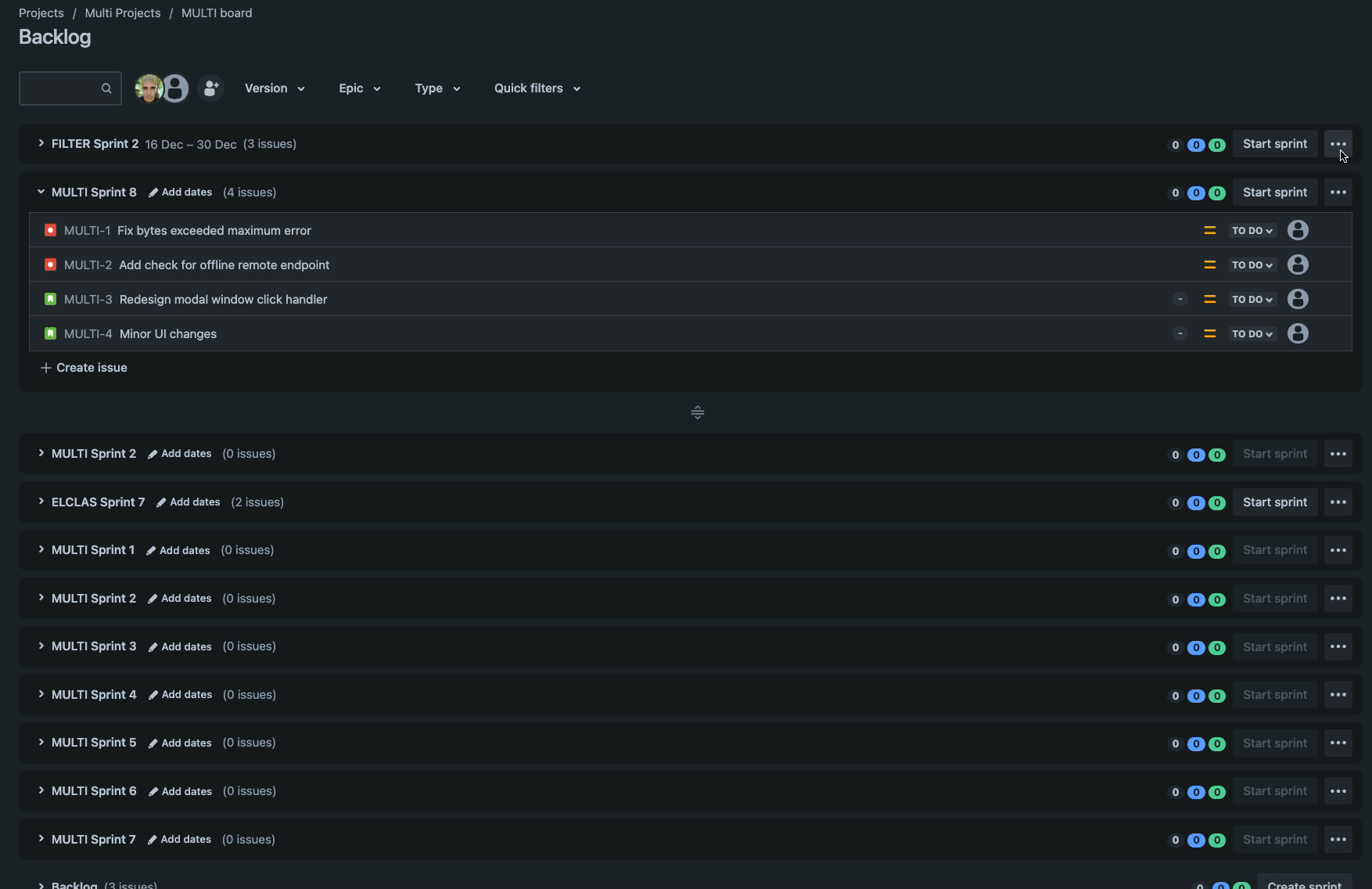
An onslaught of clicks just to get a single sprint to the top of the backlog! 😢
This displeasure quickly grew to become a common annoyance in our team. Many other Atlassian customers had also faced this issue and have made a feature request (JSWCLOUD-21509) asking us to add functionality to solve this problem.
Sprint sequences in Jira
Let’s understand how sprints are ordered in Jira. The sprints table in Jira has a SEQUENCE field which has a BIGINT PostgreSQL numeric data type. This field controls how sprints should be ordered relative to each other. A lower SEQUENCE number means a sprint should appear higher up on the backlog compared to a higher SEQUENCE number. In other words, sprints in your Jira backlog are ordered by their SEQUENCE value in ascending order.
When a new sprint is created, the SEQUENCE field is null for that sprint. The SEQUENCE will only be set to a non-null value if that sprint’s ordering is changed (i.e. the sprint is moved up by the user). If a sprint has a null SEQUENCE in the database, we fall back to using its Sprint Id (a unique numeric identifier for sprints that will always be present) as its sequence instead. The effective sequence of a sprint is its sequence value (if not-null) or the Sprint Id otherwise as a fallback.
The backlog view groups sprints into three main sections. Active sprints are pinned to the top of the backlog. Future sprints sit directly below the active sprints. The backlog, a single special sprint that cannot be deleted or moved, is pinned at the very bottom of the backlog view. Each sections sprints are ordered amongst themselves by the effective sequence value (from lowest effective sequence at the very top to highest effective sequence at the very bottom).

Backlog Sprints ordered by their effective sequence
Innovation time: Assessing the existing swap API
Atlassian is proud of its 20% time initiative in which every team member is given to opportunity to improve our software in the way that they feel is most important to them.
A few of my Atlassian colleagues and I rallied together to tackle the above problem. We wanted to add a move sprint to top and move sprint to bottom feature to complement the existing sprint actions.
Our original assumption was that implementing such a feature would be as trivial as replacing the parameters we pass in to an existing move sprint function. However, this assumption was wrong.
Jira has a Greenhopper REST API (which originates from the acquisition of the Greenhopper plugin from Green Pepper Software in 2009). This API supports a sprint swap endpoint which looks like this:
|
1 2 3 4 5 |
PUT /rest/greenhopper/1.0/sprint/{sprintId}/swap { "targetSprintId": {targetSprintId} } |
This endpoint accepts a source {sprintId} and the target {targetSprintId} and swaps the positions of only those two sprints without modifying any other sprints in between them. Therefore, we cannot use it to solve the problem at hand because we want to move a sprint to the top (and preserve ordering for all other sprints in between) and not simply swap a sprint with the top sprint.
Implementing the new move sprint API
The next task was to implement a move sprint endpoint to satisfy our requirements.
Initially, we attempted to complete a move operation using the existing backend powering the /swap endpoint. This is possible because we can achieve a move by completing multiple swaps instead. This can be thought of as a modified bubble sort where we are bubbling the source sprint to its target sprint destination one swap at a time. However, this approach was not feasible due to limitations in performance (more on this later).
Therefore, we decided to create a new move sprint endpoint that looks like this:
|
1 2 3 4 5 |
PUT /rest/greenhopper/1.0/sprint/{sprintId}/move { "targetSprintId": {targetSprintId} } |
I’ll omit notes on the technical implementation of this endpoint as this task was mostly straight forward and unremarkable.
Handling cross-project boards
Multiple boards & cross-project boards
In Jira Software, a project can be thought of as a container used to organise and track tasks, or issues, across the entire team. A board visualises and manages a subset of issues in the project. A sprint contains a more deeply refined subset of issues from the project.
There are a few configurations we must support when considering Company Managed Projects (CMP) in Jira.
A project can have multiple boards. Each board is powered by its own JQL filter which controls which issues are filtered from all issues to be included in the board. In other words, the JQL filter determines which issues you will see when you look at that boards board view or backlog view. A board belongs to only one project.
The JQL filter powering a board can include multiple projects. This is known as a cross-project board. This means that the board’s views may include issues from many different projects.
A board can have one or more sprints. Each sprint originates from one board. A sprint can have many issues but an issue belongs to only one sprint. Each issue originates from a project as denoted by its issue key. However, an issue can be moved between different sprints.
When observing the CMP backlog view, you will see all sprints that:
- contain issues that match the boards JQL filter, and
- were originally created on the board we are viewing (issues in the sprint are still hidden if they do not match the boards JQL filter even if the sprint itself is visible).
This behaviour ensures all the needed important entities are visible based on your boards JQL filter.
Speed vs. correctness
Unfortunately, this complicates our moving logic because we now have to ensure such backlogs not only support move operations but do not break relative ordering of sprints on other backlogs.
Lets consider an example with four projects who each have one board. In our setup, Project A contains a single board Board A. Project B contains a single board Board B and so on.
Board A has a JQL filter that looks like this:
|
1 |
project = ProjectA or project = ProjectB or project = ProjectC or project = ProjectD |
As explained previously, this board will now include all issues that belong to the above four projects. It will also include sprints that contain any matching issues from those projects.
Board A currently has no future sprints but all of the other boards have some future sprints. There are a total of 7 future sprints visible. All are freshly created and have a null sequence value.
Observe Boards A’s backlog view:

Note that the background colour of each sprint above corresponds to the board it was created from.
When implementing our move algorithm, our initial instinct was to only process sprints that belonged to the same board because boards most commonly only have a single project included in their JQL. However, this would not support cross-project boards. In fact, it breaks relative sprint ordering. Let’s explore why.
Consider I want to move Sprint E to Sprint B’s position. Both sprints belong to Board C. We will only process sprints that belong to Board C for this move.
This move can be visualised as:
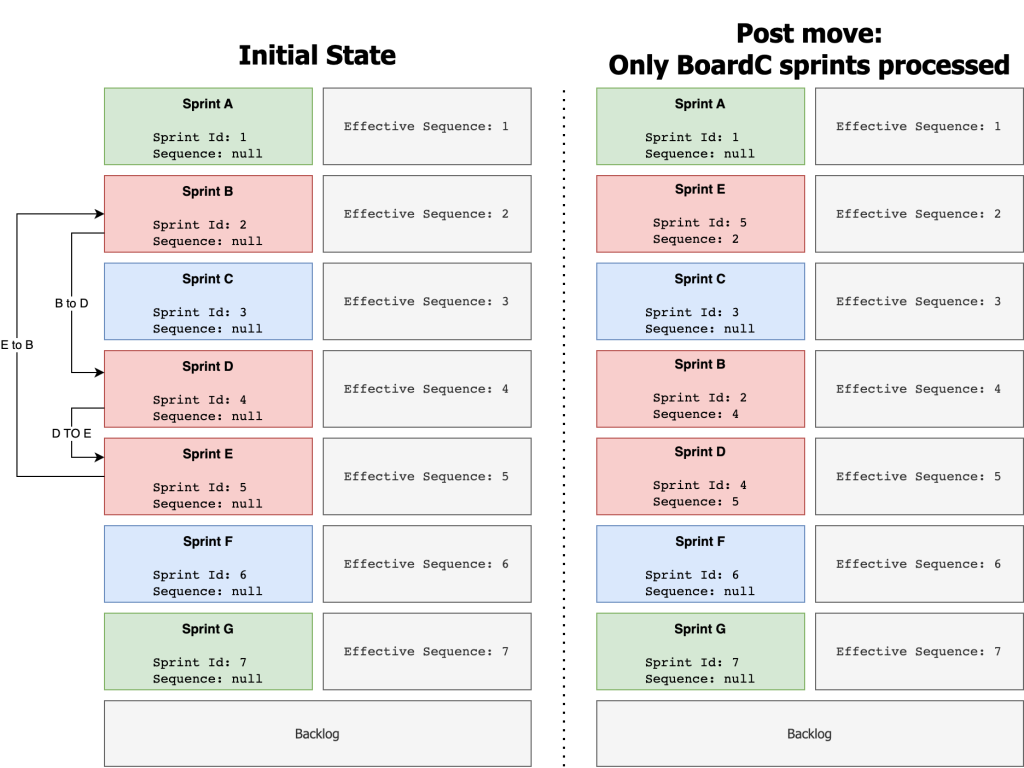
We set Sprint E’s sequence to the sequence of Sprint B. Then we set Sprint B’s sequence to the sequence of sprint D. Finally, we set Sprint D’s sequence to the original sequence of Sprint E.
If you only consider the sprints from Board C, the post move ordering is correct. Sprint E is at the top, followed by Sprint B then Sprint D. This ordering would also appear correct if you were to look at Board C’s backlog with a default board JQL (as it would only show the 3 sprints from Board C).
However, looking at Board A’s backlog as visualised above we can see the post move ordering is incorrect. Sprint B is incorrectly below Sprint C, but it was previously above it. Relative ordering was not preserved between these sprints as a result of the move.
If we instead decided to process all sprints with a sequence between our source and target sprint, we would preserve relative ordering.
This move can be visualised as:
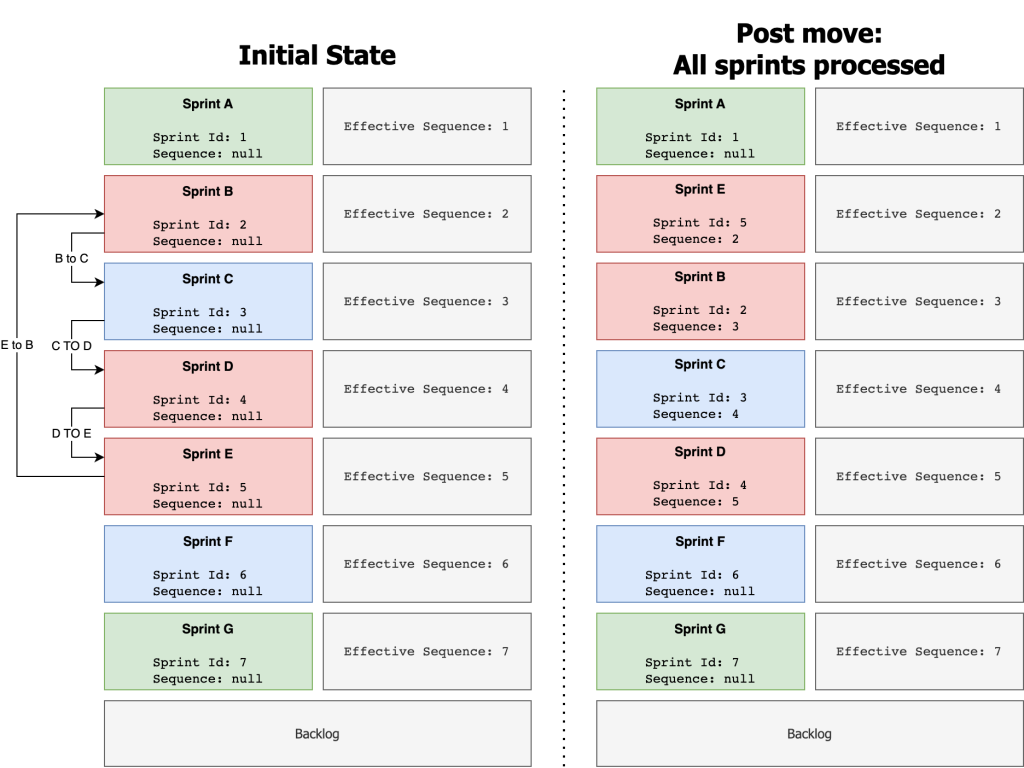
Notice how Sprint B remains above Sprint C just as it was previously. Relative ordering was preserved and this is outcome is more correct.
Therefore, to support cross-project boards, we must always process all sprints that have an effective sequence value between the source sprint and target sprint.
It is important to note that there is a trade-off here. Processing all sequences is strictly correct, preserves all sequence ordering globally and offers a great customer experience for those using cross-project boards. However, it is computationally slower. Processing only sprints in the current board we are looking at is faster but will break relative ordering for cross-project boards.
In the end we decided to process all sequences as full correctness and a great customer experience was desired and the measured performance was still very good.
Optimising for maximum performance
The new move implementation yields serious performance gains. It can process 10000 sprints in the same time as the old implementation handled 5 sprints. That is a ~200,000% performance gain!!
Performance here is measured by comparing the total request time taken to achieve a desired move via multiple /swap operation (old implementation) and via a single /move operation (new implementation).
For example, in a backlog of 5 sprints to move a sprint from the very bottom to the very top would require us to process 5 sprints. Using the old /swap implementation, this would take N-1 swaps where N is the number of sprints needed to process. This is because we would have to swap the source sprint with the sprint directly above it 4 times until it reached the very top. This results in us performing 8 total sprint updates (4 swaps x 2 sprints updates in each swap). Keep in mind there is some additional overhead in the Jira Monolith when calling the /swap function repeatedly due to additional lookups and validation. On the other hand, the new /move implementation only performs 5 total sprint updates in a single go. For 5 sprints, the old implementation takes 2.35 s (P50) whereas the new implementation takes 317 ms (P50).
Furthermore, we utilises a more efficient algorithm which yields performance improvements for even a single operation that only processes 2 sprints. One of the ways we achieved this is by taking advantage of Sprint caches in Jira Monolith to speed up our sprint fetching. Jira operates on sprints often and typically has a cache of all sprints ready at any given time.
Recall that we need to fetch all sprints between a sequence range to perform our sprint updates. We can do this by querying the database directly with a custom query or by fetching all sprints from the sprint cache and then filtering the sprints in memory using our sequence range criteria. Opting to use the cache is much faster and also reduces database load which is a benefit to the rest of the application. It is also best practice as this cache is designed to be used for heavy sprint operations in Jira.
This provides us with great performance improvements when processing 2 sprints. The old implementation takes 717 ms (P50) whereas the new implementation takes 300 ms (P50).
Another limitation with the old implementation is that requests to Jira monolith will time out after 60 seconds. Therefore, the operation would fail even if we ignore the poor performance when processing a large number of sprints.
You can explore the full performance comparisons in the table below:
| Number of Sprints Processed | /swap (Old Implementation)Request Time (P50) | /move (New Implementation)Request Time (P50) |
|---|---|---|
| 2 | 717 ms | 300 ms |
| 5 | 2.35 s | 317 ms |
| 10 | 3.78 s | 322 ms |
| 20 | 6.04 s | 327 ms |
| 50 | 13.85 s | 339 ms |
| 100 | 25.62 s | 352 ms |
| 200 | 53.80 s | 371 ms |
| 500 | Too slow! Request timeout after 60s! | 410 ms |
| 1000 | Too slow! Request timeout after 60s! | 650 ms |
| 2000 | Too slow! Request timeout after 60s! | 876 ms |
| 5000 | Too slow! Request timeout after 60s! | 1.56 s |
| 10000 | Too slow! Request timeout after 60s! | 2.34 s |
| 20000 | Too slow! Request timeout after 60s! | 8.59 s |
| 50000 | Too slow! Request timeout after 60s! | 10.46 s |
| 100000 | Too slow! Request timeout after 60s! | 25.50 s |
It is important to note that most move operations will not touch many sprints at all. Even our oldest and largest customers have at most 150k sprints on their Jira tenant. The vast majority of these sprints will be closed sprints. Our metrics show us that overwhelming majority of move operations will process 1000 sprints at most.
Duplicate Sequences Bug
During early stages of testing we soon encountered what would be the most interesting problem to solve as parting of delivering this feature.
In the database, SEQUENCE is a standalone numeric field and is not a relational field. This means its possible to have two sprints with the same effective sequence. The problem here is that we cannot have deterministic ordering if any two sprints have duplicate sequences. This leads to a backlog sprint order which is undefined and hints at data inconsistency issues.
Consider this scenario where sprintId 2 and sprintId 3 have the same sequence.
| sprintId | SEQUENCE |
|---|---|
| 1 | null |
| 2 | 2 |
| 3 | 2 |
| 4 | null |
Or this scenario where sprintId 1 and sprintId 3 have the same sequence. Recall that sprintId 1 has an effective sequence of 1 due the fallback logic which sets its sequence to its sprintId if SEQUENCE is null.
| sprintId | SEQUENCE |
|---|---|
| 1 | null |
| 2 | 2 |
| 3 | 1 |
| 4 | 4 |
Customers had reported issues with duplicate sequences in this ticket: JSWCLOUD-21024
The only code that mutated the SEQUENCE field in Jira was the swap sprints endpoint. Recall that this is an endpoint that has existed in Jira for many, many years. It was therefore logical to investigate this code for any bugs that could lead to the database storing duplicate sequences.
Lets take a closer look for the code responsible for handling the database updates of sprints:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
public ServiceOutcome<Void> swapSprints(Sprint sprintA, Sprint sprintB, Long sequenceA, Long sequenceB) { final List<Sprint> sprintsToUpdate = Lists.newArrayList( Sprint.builder(sprintA).sequence(sequenceB).build(), Sprint.builder(sprintB).sequence(sequenceA).build() ); final PartialUpdate partialUpdate = new SequenceUpdate(); for (int index = 0; index < sprintsToUpdate.size(); index++) { ServiceOutcome<Sprint> outcome = updateSprint(sprintsToUpdate.get(index), partialUpdate); if (outcome.isInvalid()) { return error(outcome); } } return ok(); } |
In this method we accept two sprints sprintA and sprintB alongside their current sequence values via sequenceA and sequenceB. We build a sprintsToUpdate list which includes two sprints to update. We set sprintA's sequence to sequenceB and sprintB's sequence to sequenceA. This effectively completes a swap in ordering.
In the main loop, we iterate over all sprints that we need to update and make a call to updateSprint(). This call will either succeed or fail. If it fails, outcome.isInvalid() will be false and we will return an error. Otherwise, if there are no errors we will return ok() after exiting the loop.
I have omitted the code for updateSprint(), it utilises a Sprint DAO object to write the changes for a single sprint to the database. It is heavily tested and appears to be very reliable. However, it can occasionally fail or time out in rare cases when there is contestation on the table as a whole or when row-level locks are present which prevent writing to specific rows.
The issue here is a race condition which can lead to the first update succeeding but the second updating failing. For example, consider two customers Alice and Bob. Alice is attempting to perform the operation swap(sprintA, sprintB). At the same time Bob is performing a long running sprint operation on sprintB which has triggered a row-level lock on sprintB in the sprints table.
We follow through the code for Alice’s request and see that we can successfully call updateSprint() for sprintA with no issues in the first loop iteration. We have persisted sprintA in the database with a sequence of sequenceB. In the second loop iteration, our call to updateSprint() fails as sprintB is currently row-locked by the long running sprint operation Bob has triggered. This call immediately fails and we exit the method and show an error message to Alice. However, we never update sprintB’s sequence to sequenceA. Therefore both sprintA and sprintB now currently have a sequence that equals sequenceB which is a duplicate sequence that has been persisted in the database.
Our solution here is to introduce a database transaction to ensure all or nothing updates for the entire batch of sprints. This is best practice and enforced all across Jira but was missed in this specific instance. The transaction ensures any failure in persistence of data leaves the existing data in a consistent state.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
public ServiceOutcome<Void> swapSprints(Sprint sprintA, Sprint sprintB, Long sequenceA, Long sequenceB) { final List < Sprint > sprintsToUpdate = Lists.newArrayList( Sprint.builder(sprintA).sequence(sequenceB).build(), Sprint.builder(sprintB).sequence(sequenceA).build() ); final PartialUpdate partialUpdate = new SequenceUpdate(); try { transactionSupport.executeInTransactionThrowingException(() - > { for (int index = 0; index < sprintsToUpdate.size(); index++) { ServiceOutcome < Sprint > outcome = updateSprint(sprintsToUpdate.get(index), partialUpdate); if (outcome.isInvalid()) { return error(outcome); } } } } } catch (Exception exception) { LOG.withoutCustomerData().warn(exception.getMessage()); return error(ErrorCollection.Reason.CONFLICT, "gh.api.sprint.error.version.mismatch"); } return ok(); } |
The rare occurrence of this bug led to a delay in its patch. It is very uncommon for two customers to initiate sprint swap requests with overlapping sprints at the same time. This is why there have only been a handful of occurrences of this bug over the past 10 years. Based on customer reports, it would appear as if this bug mostly affect large enterprises with a lot of users working in the same projects (and hence more likely to update the same sprints at the same time).
The introduction of a transaction fixed new instances of the duplicate sequence bug from occurring. However, there were still thousands of tenants out there with bad data in their database as a result of the bug occurring previously before the patch. Affected customers would receive an error when attempting to swap or move sprints that had duplicate sequences. Customers would then need to contact the Atlassian support team who would then take backups of their table and manually patch their database using a patch script.
Ultimately, this is a huge pain point for our customers and requires manual effort and takes up their valuable time. We were highly motivated to improve this situation for both customers and the Atlassian support team (to reduce their workload).
The innovation team put their heads together to find a solution. Initially, we considered using a once-off database upgrade task to patch the issue across all tenants which is best practice for most use cases. In our case however, it was not immediately clear if there were other problematic code paths in Jira monolith that could result in the duplicate sequence bug. For example, the bug could resurface due to a server to cloud migration flow or other code that is operating on sprints but is lacking a transaction. This would potentially require us to create multiple upgrade task to address the problem which was not desirable.
We finally decided to implement an asynchronous global tenant patch. Whenever we detect a duplicate sequence in the database, we would fail that immediate request and trigger a patch operation in the background. Failing the immediate request is a sub-optimal user experience but was accepted as a trade-off given the rarity of its occurrence. Also blocking the request on a synchronous patch would be undesirable as it would be a poorer experience overall. We utilise a queuing system for such background takes in Jira and the speed at which our background task is processed can be variable. However, our metrics show it typically is completed within a few seconds.
The background patch operation would asynchronously go through the database and reset all sprints with duplicate sequences to null. As this is a global patch we expect it to run once per tenant. After a single patch, the data should be in a consistent state and all future move operations should succeed without encountering the duplicate sequence issue. We expect to eventually deprecate and retire this patching code once we have confirmed all code paths that operate on sprints are robust and consistent.
It is interesting to note that this patch is a recursive operation as setting a sprints sequence to null could in turn spawn new duplicate sequences.
Consider the following case:
| sprintId | SEQUENCE |
|---|---|
| 1 | null |
| 2 | 2 |
| 3 | 2 |
| 4 | 3 |
After setting the sequence of sprintId 2 and sprintId 3 to null, we introduce a new duplicate sequence between sprintId 3 and sprintId4 which both now have an effective sequence of 3:
| sprintId | SEQUENCE |
|---|---|
| 1 | null |
| 2 | null |
| 3 | null |
| 4 | 3 |
Therefore, we must also reset sprintId 4’s sequence to
null.
The implementation of this patch is huge win for saving our customers and the Atlassian support team valuable time!
Delivering a collection of improvements to customers
The innovation team was accomplished in delivering a collection of improvements to customers.
We have implemented a new, performant, flexible move sprint API. We have fixed a long standing data inconsistency issue in Jira and implemented an automated patch for a previous manual and tedious operation for both customers and the Atlassian support team.
There is now also a lower barrier to entry for teams at Atlassian to build other features like drag & drop sprints on the backlog.
At Atlassian, many small and big features get shipped not as planned roadmap projects but through innovation time which is available to all team members. Different team members come together combining their unique perspectives and skillsets to solve real problems just like this one for our customers.
In the end, our innovation team is happy to be saving customers a lot of clicks going forward!